Productivity Automation with n8n
I gave back 4+ hours a week by building a pipeline that turns raw Jira issues into a Notion roadmap and a Confluence stakeholder report, refreshed automatically every morning, so the status everyone needs is ready before anyone asks. Proof that I do not just manage process; I automate it.
Status lived in Jira; nobody had the big picture
Project status lived in Jira at the issue level, but two audiences needed something Jira didn't give them. PMs needed a single high-level roadmap view across all projects, and stakeholders needed a clean, regular report they could actually read.
Both were assembled by hand: someone pulled issues from Jira, normalized statuses, updated a dashboard, then rewrote it into a stakeholder report. Repetitive, easy to skip when busy, and always slightly stale by the time anyone looked.
Two scheduled workflows, one daily pipeline
I built two n8n workflows that hand off to each other, both on a morning schedule. The first makes Notion the single source of truth; the second turns that into a stakeholder-ready Confluence page, with no human in the loop.
Jira issues
getAll: issue
MapStatus
normalize statuses
Notion roadmap
source of truth
Confluence report
for stakeholders
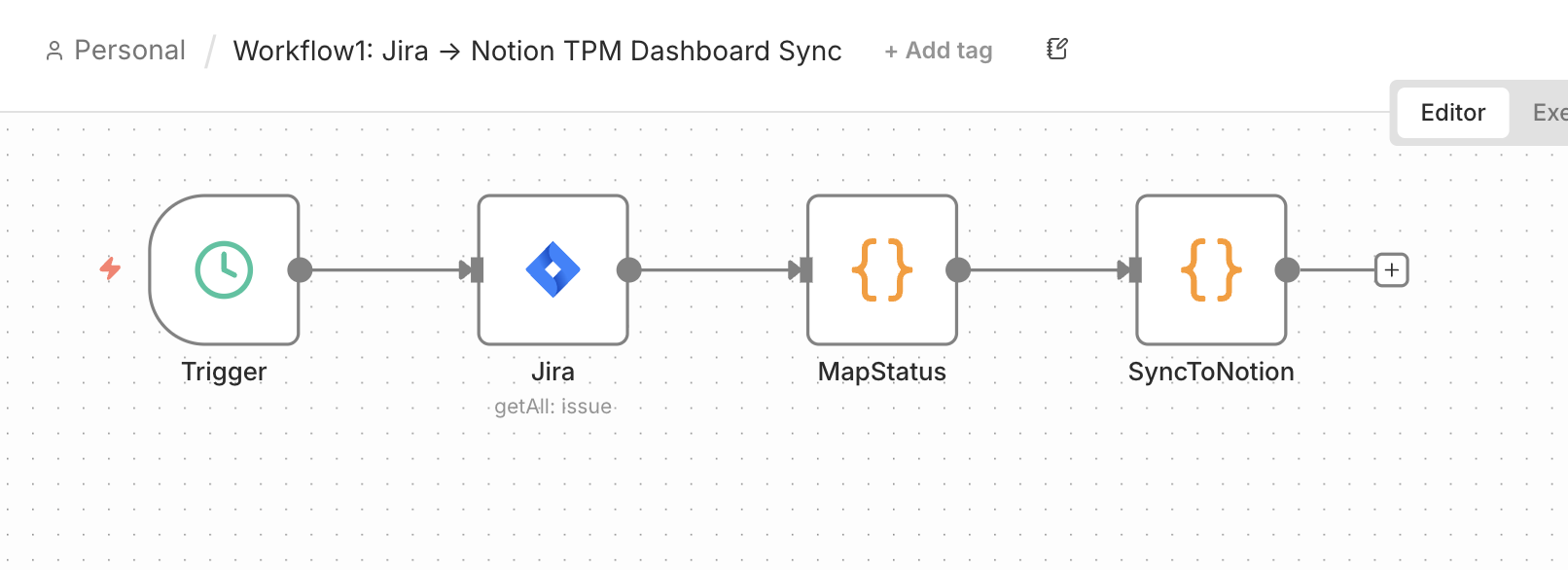
Jira → Notion TPM Dashboard Sync
A morning Schedule Trigger pulls every Jira issue, a MapStatus step normalizes the workflow's many status values into a clean set, and SyncToNotion writes them into a Notion database: the high-level roadmap view of all projects.
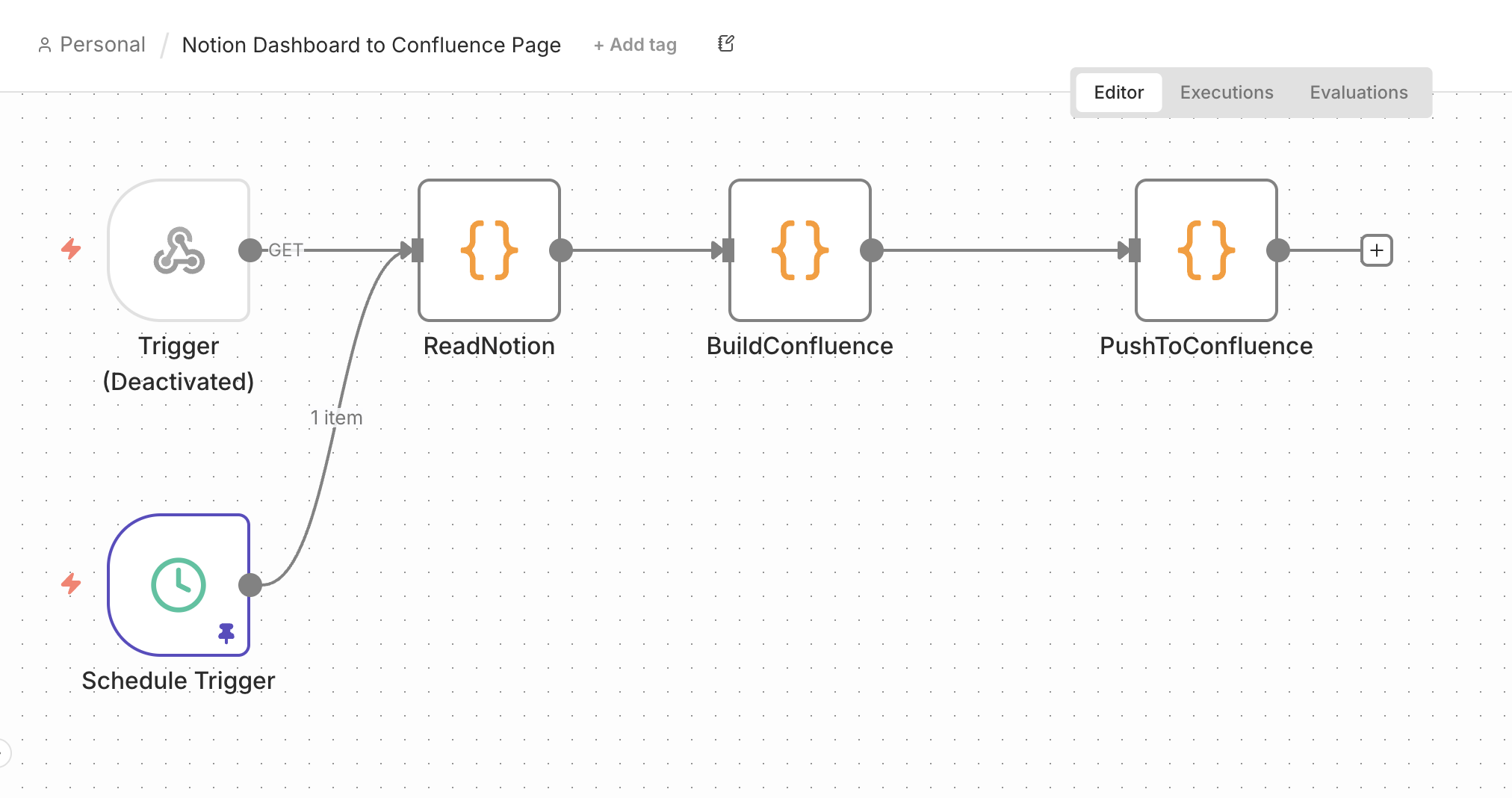
Notion Dashboard → Confluence Page
A second morning Schedule Trigger reads the Notion roadmap (ReadNotion), BuildConfluence formats it into a readable status page, and PushToConfluence publishes it: the stakeholder-facing report, current as of that morning.
Time back, and nothing slips
4+ hrs
saved per week
~10
stakeholders on the Confluence report
~12/day
overdue items surfaced across 20+ projects
The qualitative win: Notion became the single source of truth for the roadmap, and stakeholders got a fresh Confluence report every morning without anyone assembling it. The team shifted from chasing status to acting on it.
What I'd improve next
- check_circleAlerting thresholds. Trigger an immediate ping when overdue items cross a threshold, instead of waiting for the next morning refresh.
- check_circleSelf-serve config. Let each team tune its own filters and recipients without editing the workflow directly.
- check_circleResilient error handling. Add retries and failure alerts on the Jira, Notion, and Confluence API calls so a transient outage can't silently leave the morning report stale.